
Posted on: 2023 Aug 31
在今年年初的早些时候马斯克收购 Twitter 时表示会对 Twitter 的推荐算法进行开源。在 2023 年三月份的最后一天,Twitter 的推荐算法代码如约而至地出现在了 GitHub 上。开源推荐算法对 Twitter 公司和用户来说,在一定角度上,是一件双赢的事情。
对于 Twitter 公司来说,其近些年来遇到了信任危机:用户不清楚不同推文的出现理由导致怀疑 Twitter 公司收黑钱做竞价排名的事情。开源 Twitter 推荐算法的官方理由,马老板也给出了自己的解释:
一方面,现有的推荐「算法」太过错综复杂以至于 Twitter 内部都无法很好地搞懂,而开源能够让公众直视当下糟糕的「算法」起到监视的作用,从而推动 Twitter 公司的开发进一步快速迭代「算法」,尽管代码开源初期由于糟糕的「算法」会让 Twitter 陷入尴尬的境地;另一方面也是最重要的一点,Twitter 希望以此来解决上述提到的信任危机。
对于普通用户来说,了解 Twitter 的推荐算法一定程度上能够帮助自己的推文更好地被推荐到更多用户的时间线上,给自己增加更多的曝光流量。如果是一个推荐系统的开发者,还能从顶级公司的推荐系统中学习到有用的策略;科研工作者也能通过分析应用中使用的算法得出研究结论辅助改进算法 ^1。
本篇文章就是一起来探索一下推荐算法的重要性,什么是推荐算法,以及 Twitter 推荐算法的做法。
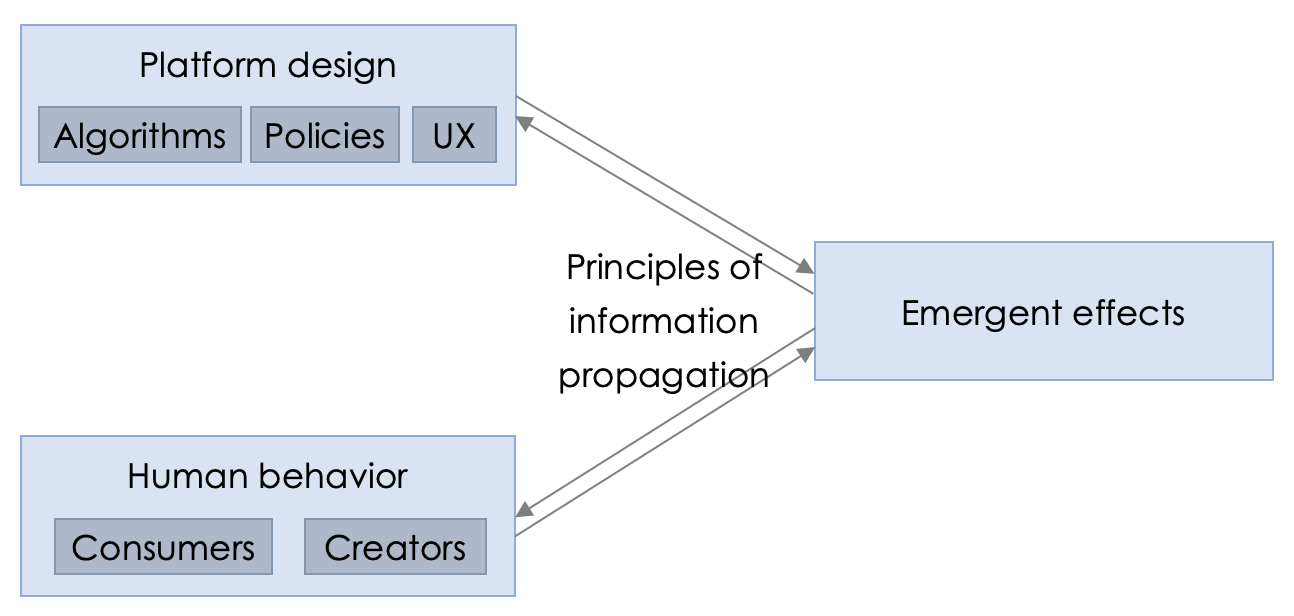
哥伦比大学下的一个研究机构 Knight First Amendment Institute(下称,the Knight Institute)曾指出 ^2,社交媒体平台的推荐系统,特别是其内部的算法和策略,对人们的行为有着巨大影响,包括平台用户和内容创作者。反之,用户和创作者的行为也会反向影响平台,推动算法和策略的持续更新。许多社交媒体上的负面现象常被归咎于人们的行为或是相关算法,但实际上,这些现象是两者共同作用的结果。
The Knight Institute 也列举了两个常见于舆论的不良现象(从观察的角度 vs 从猜想的角度):
这也很好地反映了我们在引言中所提到的、由于算法透明度不足引发问题。人们会对这种不透明的算法产生了许多疑虑。然而,对算法进行开源确实可以减少这部分的疑虑,因为信息传播的方式对于不少人来说其实是透明度的。
另一方面,现代网络的高速传播能力容易引发病毒式扩散,相信大家对此有深刻的体会,其中假新闻的传播尤为常见。
The Knight Institute 指出,网络的存在推动了病毒式的信息传播。这个观点其实很容易理解,因为在互联网网络的前提下,信息才能被更广泛传播。而在现代网络中,我们可以通过度量某个信息(例如,一个推文被转发了多少次)的传播能力,来了解其在网络中的影响力。然而,病毒式的信息传播有时会变得无法预测,并且其传播的内容常常占据了我们的大部分注意力。但是,一个所谓的「降权」操作,或者说是一种软屏蔽,可以有效地减缓这种病毒式的信息传播。
然而,降权这种操作通常在平台内部进行,用户通常无法确切知道自己是否被降权。当用户发现自己的推文无法获得广泛传播时,他们就会怀疑自己的推文是否被降权,这也就进一步佐证了推荐算法的不透明性可能引发用户的疑惑和揣测。所以,开源化推荐算法可以变相地解决某个企业的信任危机。
说到推荐算法,很多人对里面的两个词都很熟悉,但是放在一起又不能说出个细节来。这里我尝试举一个极简的例子来一起说明推荐算法要做的事情。
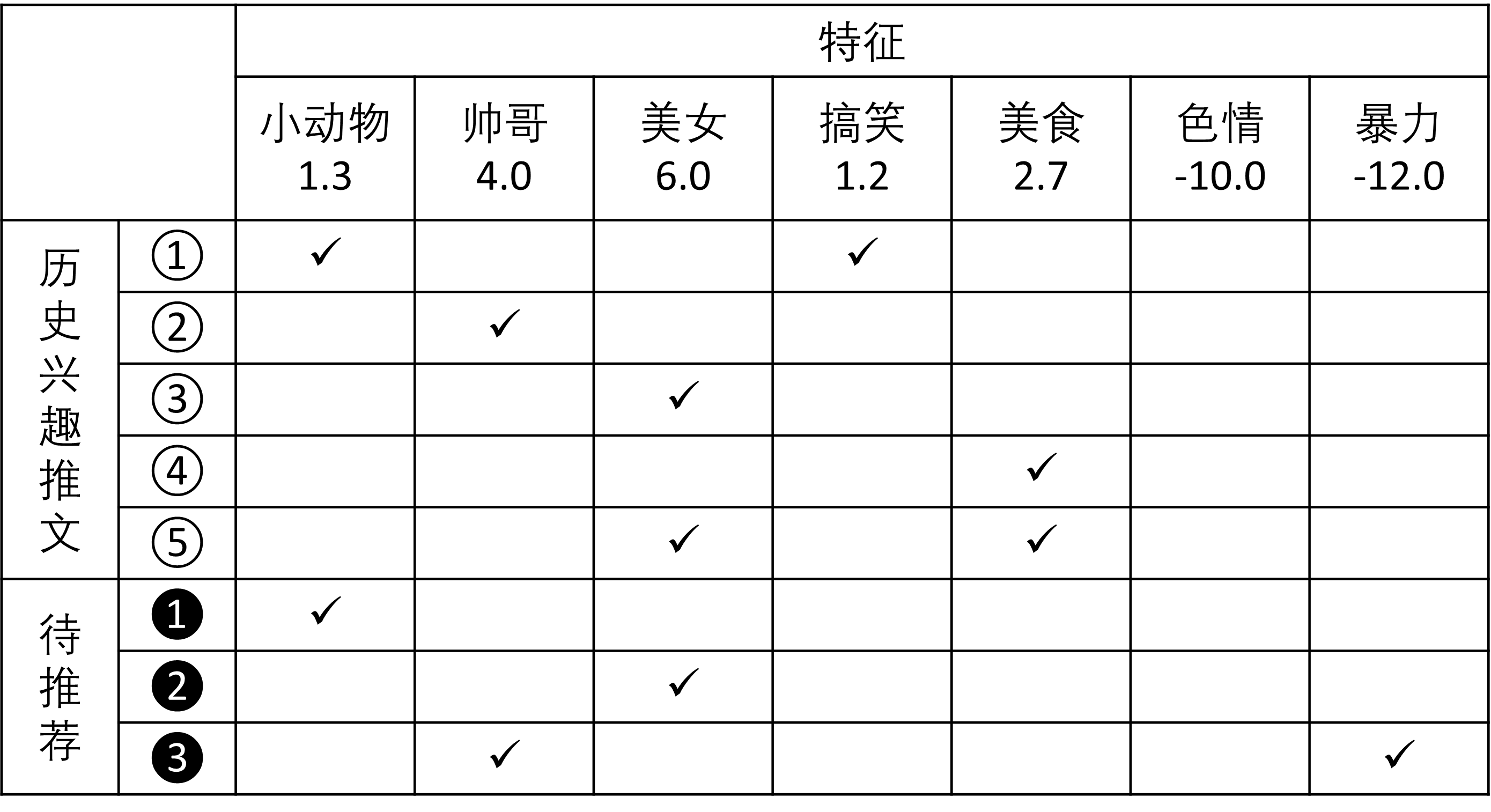
上图中,① – ⑤ 代表了某一个用户浏览记录中比较感兴趣的推文,❶ – ❸ 分别为三条待推荐的推文,右边的表格记录了推文各自对应的标签(这里称为「特征」),标签下面的数字为该特征对应的权重。而接下来的任务是,根据用户可能的感兴趣程度排序 ❶❷❸ 这三条推文作为出现在用户时间线上的顺序。
这个任务看起来很简单吧,稍加思考就能知道最优的排序为 ❷❶❸ 。但是同时这个例子也给我们揭露了推荐算法的很多细节和本质任务:
这就是大部分推荐系统都要做的事情,里面可能有很多的真正的算法被应用了,尽管我们常说推荐算法这四个字。由此也可得知,为什么引言图中马斯克的「算法」二字很严谨地加了一对引号。如果真要算算法的话,可能是其中的基于相似度的排序算法。
推荐系统可以被理解为一个加入了内容定制的“算法”,如果用生活场景类比一下的话,可以是一个了解你口味的高级专人服务员。
这样的服务员了解你的口味,他知道你以前点过什么菜,你对哪些菜评价比较高。当你去餐厅时,他会根据你的历史选择和偏好,为你推荐一些你可能喜欢的菜。这就像推荐系统的「协同过滤」部分,通过你的历史行为和其他类似你的人的行为,来推测你可能会喜欢什么。
同时,这个服务员也了解每道菜的具体成分和特点,比如哪些是辣的,哪些是素的,哪些含有某种你喜欢的食材。这就像推荐系统的「内容过滤」部分,根据产品的需求,制定合适的策略,从而过滤掉不符合你的兴趣的。
但是,如果这个服务员只按照你的历史喜好来推荐,你可能会觉得乏味。他还需要时不时地给你推荐一些新的,你从未尝试过的菜品。这就像推荐系统的「探索与利用」问题,既需要满足你的已知喜好(利用),也需要引导你发现新的喜好(探索)。
此外,这个服务员也需要考虑到当前的情况,比如如果今天天气很热,他可能会推荐一些清凉的菜品;如果你今天带了小孩,他可能会推荐一些适合孩子的菜。这就像推荐系统的「上下文感知」,它不仅需要考虑你的长期喜好,也需要考虑到当前的特定情境。
而最终整个“算法”的整体表现都会被归纳为一个推荐系统,至于其中各个部分是否存在以及什么样的策略被应用,会因各大推荐系统的实现而异。
了解完基础的内容,下面就来看看 Twitter 大公司的推荐系统到底是怎么做的。
把每一个用户点击、阅读、评论的行为都记录下来是不现实的,因为这样会造成存储需求的持续膨胀。现在让我们来做一个简单的计算。假设一个点赞行为记录需要 512bit 的数据(这是一个非常保守的估计,实际的数据可能更大,还没算存储需求更大的评论行为),一个网站每天有 100 万的活跃用户,每个用户平均产生 100 个行为,那么每年就会产生 17TB 的数据,而且这还只是一个中等规模的网站的数据。
考虑到存储和处理大量用户行为数据的挑战,Twitter 选择了一种更为高效的方式来进行推荐,那就是基于模型的协同过滤。从排序器的描述中可以得知,Twitter 统计用户一段时间内的各种交互行为和关系图谱作为特征,喂给一个深度神经网络(i.e., MaskNet)预测出用户对于一条推文的各种交互的概率,然后通过预设的权重计算出推文的排序值。那么,什么是特征呢?在机器学习中,特征是用来描述样本的某种属性的。例如,如果我们要预测一个房子的价格,那么房子的面积、位置、房间数量等明显和房价有强相关的属性会作为特征,甚至房子当地的气候环境、周边的历史事件等弱相关的属性也能作为特征。而机器学习能够自动从输入的表层特征中提取更深层次的隐藏特征并拟合到训练样本中。
接下来,我们来看看一个更具体的官方例子:
user_aggregate_v2.pair.recap.engagement.is_favorited.engagement_features.in_network.replies.count.50.days.count
这串超长的字符串指示了该特征统计的是在 50 天内用户收藏的推文中有回复的推文数。用例子来说的话,让我们假设有一个叫做 Alice 的 Twitter 用户。Alice 每天都浏览 Twitter 且经常收藏和回复推文。他在过去的 50 天内,收藏了 100 条推文,其中有 30 条推文是他回复过的。那么,这个特征的值就是 30。
这个特征会告诉了后续的算法在过去的 50 天内,对他喜欢的推文进行了多少次回复。这是一个反映用户兴趣和行为的重要信息,可以被用来预测 Alice 对于新的推文的兴趣。
在实际的应用中,Twitter 会使用数百甚至数千个这样的特征来描述和预测用户的行为。
在 Twitter 的例子中,他们使用了非常多的统计信息作为特征来刻画用户的行为。这些特征包括了用户的各种历史行为(例如点击、喜欢、回复等),以及用户的关系图谱(也就是用户和其他用户的关系)。这些特征被用来预测用户对于一条推文的交互概率,然后聚合从而决定推文的排序。
如果细看官方列出的整个特征列表(至少有数百个特征),几乎所有可能和兴趣有关系的行为都被枚举了,上至你上一秒是否点击了转发按钮,下至你用什么设备发送推文,都在 Twitter 的考虑之中。
推特为用户生成的待排序候选推文主要来源于三个方面:Twitter 搜索系统中的索引(search-index),用户与推文的知识图谱(user-tweet-entity-graph, UTEG),以及用户可能感兴趣的别的用户发的推文(follow-recommendation-service, FRS)。
首先是 Twitter 搜索系统的索引,这部分主要包含了 Twitter 上的热门搜索内容,也就是我们常说的「热搜」。热搜往往是大量用户关注或讨论的主题,所以它们具有很高的可见度和影响力。比如,当某个明星的新闻或某个社会事件在 Twitter 上被广泛讨论时,这些内容就可能出现在热搜中,并成为候选推文。据统计,大约有 50% 的推文来自于这个来源。
其次就是用户与推文的知识图谱,这是由 Twitter 开源的 GraphJet 框架生成的一种数据,它可以帮助 Twitter 理解用户与推文之间的关系。比如,如果你经常点赞、转发或评论某个话题或某个用户的推文,这些行为就会在知识图谱中形成相应的连接,GraphJet 就会基于这些连接为你推荐相关的内容。举个例子,如果你经常在 Twitter 上分享和评论科技相关的推文,那么 GraphJet 可能就会认为你对科技感兴趣,并在你的候选推文中加入更多科技相关的内容。
最后则是用户可能感兴趣的其他用户的推文,这部分推文来自于 Twitter 的关注推荐服务。这个服务会根据你的行为和偏好,推荐一些你可能感兴趣但尚未关注的用户的推文。比如,如果你经常关注和互动与旅行相关的推文,那么 Twitter 可能会推荐一些旅行博主的推文给你。
上面说到,Twitter 通过预测出用户对于一条推文的各种交互的概率,然后通过预设的权重计算出推文最终的排序值。潜台词就是说,用户愿意交互的推文都强相关于他们的兴趣范围。
从排序器的页面中可以找到,截止到 2023 年 4 月 23 日,Twitter 考虑的交互行为有以下 10 种以及它们对应的权重:
可以看到,举报行为的权重远大于其它所有的行为(权重:-369.0),而观看视频这一行为几乎无足轻重于兴趣(权重:0.005)。其中两个对兴趣影响较大的行为是用户和推文作者的互相响应(权重:75.0)和用户对推文的一些负面行为(权重:-74.0)。
综合来看,要想推文出现在更多用户的时间线上,需要让推文更加吸引用户做出交互(收藏/转发/回复),积极响应其它用户的评论,以及避免被其它用户举报。但是权重可能会被调整,需要偶尔回来开源仓库中查看一下最新的策略。

总的来说,用户的时间线由三部分组成:根据用户兴趣排序的推文、广告,以及用户关注的人的推文。其中,已排序的推文还需要经过一个过滤的操作来满足平台的策略。接下来让我们每部分拆开来一点一点来聊一聊:
Twitter 使用一个复杂的算法(称为 HEAVY RANKER)来产生排序好的用户可能感兴趣的推文,也就是我们上面部分聊到的排序的三个重要方面。然后,这些推文需要通过一个过滤器才能出现在用户的时间线上。
关于过滤器的 Rules and Policies,仓库中相关的源码部分并没有相关的说明部分。但可以从图中得知,Twitter 考虑了用户的多样性和内容的多样性,以及公共安全。从源码的实现中也发现了 hard filtering 和 soft filtering 的字眼,对应于屏蔽和降权等操作。
广告和关注的人的推文这两个部分比较好理解,Twitter 依赖于广告产生收入,因此曝光度最高的时间线中出现广告是非常常见的现象。而关注的人发送的推文,默认用户一定对其十分感兴趣。
最后是 Mixing 的部分,值得注意的是,推特的广告不是在待排序推文中给你推荐的,而是系统直接混合进来的(可能跟你的兴趣没什么关系)。至于以何种比例和顺序做混合,仓库中有相关的开源代码但没有相关的明确说明,需要从源码中仔细推敲,感兴趣的读者可以自行探索。
尽管上面分析的推荐算法是相对公平的,但也仅截止到推荐系统的 Heavy Ranker 的部分,一般情况下大公司们都会在后处理阶段(i.e., Heuristics & Filtering)夹带私货。开头说到代码开源初期由于糟糕的「算法」会让 Twitter 陷入尴尬的境地,也确实有很多有意思的发现被热心的网友们捕捉到了。

比如,有网友在代码里发现了一些特殊的片段,比如对于「特定人群」的推文标记。上述代码阐明了 Twitter 会基于作者的身份来对推文区分或标识,包括作者是否为民主党或共和党人士,以及高级用户。
当然最令人瞩目的还当属 author_is_elon 的一部分,因为在马斯克大刀阔斧对 Twitter 内部进行重组的时候他就曾要求工程师提高其推文的曝光度,于是在相当一段时间中,即便你此前从未关注埃隆·马斯克本人,他的推文也会像幽灵一般出现在更多用户的时间线中,以至于在那个时期有不少用户不胜其扰而选择将其屏蔽。
在上述代码被曝光没多久,Twitter 官方便迅速地将上述代码片段删除并强制重新推送覆盖了代码仓库的内容。然而,时至今日你依然能在 GitHub 上搜到其他人 Fork(相当于复制)后的原始版本,开源的好处在这种情况下对于 Twitter 来说反而是由「蜜糖」转变为「砒霜」,因为一旦代码开源了,那么只要有人留有备份就无法永远抹去痕迹。
可话又说回来,至于 Twitter 官方在内部是否依然保留这部分代码逻辑仍不得而知。
Twitter 是一个言论相对自由的平台,除了一般的推文之外,还允许「其他声音」存在,但这并不意味着完全地放任自流,比如 Twitter 在推荐算法中专门搭设了一组名为「Trust and Safety」的模型来对这些弦外之音进行探测并处理。当中主要针对三部分内容:NSFW、Toxicity 以及 Abuse。
所谓的 NSFW 即是 Not Safe/Suitable For Work 的缩写,泛指不适宜在工作场合浏览的内容,而这在 Twitter 上主要特指成人内容,包括文字性话题、图像、视频等。
而 Toxicity 表示有害性的内容,如侮辱或某种类型的骚扰、某些与政治或种族相关的内容等,但这并不违反 Twitter 的服务条款;
除此之外,Abuse——也就是滥用性内容——特指那些违反 Twitter 服务条款的行为,譬如仇恨言论、有针对性的骚扰和辱骂行为等。在 Twitter 所公开的源码中还包含了更为具体的行为标签,如有惩罚性行为的内容、自残行为相关的内容或是其他违规内容。

Twitter 官方在源码仓库中有所说明,除了上述部分之外还有一些模型和规则,但出于对抗性的考量并未公开;但即便如此上述部分的代码也有不少阉割的地方,无法完全窥探 Twitter 在处理这些内容时的核心要义。
总的来说,Twitter 公司开源其推荐算法,对于用户和竞争对手来说都是好事。最后贴一个 Twitter 开源推荐算法仓库的地址:https://github.com/twitter/the-algorithm,大家可以各取所需。
Contact me if you have any comments or questions about this aritcle.
Appriciate if you would like to support me if the article really helps you.